Analyzing Text Data
Last updated on 2026-03-02 | Edit this page
Overview
Questions
- What quantitative analysis operations can be performed on data composed of literary texts?
- How can these operations be translated into Python code?
Objectives
- Learn how to perform word frequency analysis on literary texts.
- Learn how to visualize a word cloud from a text.
- Learn how to perform keyword-in-context analysis on literary texts.
In the previous episode, we worked with tabular data and performed three core operations often used in quantitative humanities research: counting, searching, and visualizing. In this episode, we’ll apply similar operations to text data. We’ll focus on analyzing the full texts of plays written by two prominent English playwrights from the 16th century: William Shakespeare (1564–1616) and Christopher Marlowe (1564–1593). We’ll learn how to perform the following types of analysis on these texts using Python:
- Word frequency analysis
- Creating a word cloud
- Keyword-in-context (KWIC) analysis
Because text fundamentally differs from tabular data, we’ll take a completely different approach in this episode compared to the previous one, using distinct Python libraries and syntax to carry out analytical tasks.
To save the data locally on your computer, go ahead and run the
following Python code. It creates a directory named data in
the same path where your Jupyter Notebook is located, if the directory
doesn’t exist already. Then, it downloads the directories
shakespeare and marlowe and their contents
from GitHub and saves them in data.
PYTHON
import os
import requests
# Base URLs for each directory
base_urls = {
"shakespeare": "https://raw.githubusercontent.com/HERMES-DKZ/python_101_humanities/main/episodes/data/shakespeare",
"marlowe": "https://raw.githubusercontent.com/HERMES-DKZ/python_101_humanities/main/episodes/data/marlowe"
}
# Files to download
file_lists = {
"shakespeare": ['alls_well_ends_well.txt', 'comedy_of_errors.txt', 'hamlet.txt', 'julius_caesar.txt',
'king_lear.txt', 'macbeth.txt', 'othello.txt', 'romeo_and_juliet.txt', 'winters_tale.txt'],
"marlowe": ['doctor_faustus.txt', 'edward_the_second.txt', 'jew_of_malta.txt', 'massacre_at_paris.txt']
}
# Create 'data' folder and subfolders
os.makedirs("data/shakespeare", exist_ok=True)
os.makedirs("data/marlowe", exist_ok=True)
# Download each file
for author, files in file_lists.items():
for file_name in files:
url = f"{base_urls[author]}/{file_name}"
local_path = f"data/{author}/{file_name}"
response = requests.get(url)
if response.status_code == 200:
with open(local_path, "w", encoding="utf-8") as f:
f.write(response.text)
print(f"Downloaded: {local_path}")
else:
print(f"Failed to download {url} (status code: {response.status_code})")For now, it’s not necessary to go into details about how the above code functions. You’ll learn more about web scraping in later episodes.
In Jupyter Notebook, save the path to each directory in a variable like this:
When working with text data, it’s essential to clean the text before beginning the analysis. During this cleaning process, you will remove characters that indicate line breaks and other unwanted symbols that might affect your analysis. I’ve performed some minimal cleaning on the text data we will be using in this episode.
Unfortunately, we won’t be able to cover text cleaning in detail in this lesson. However, you’ll find a wealth of helpful video tutorials online that can guide you through the process of cleaning text data on your own.
1. Word Frequency Analysis
Word frequency analysis is a foundational method in computational literary studies that involves counting how often individual words appear in a text or a collection of texts. By quantifying language in this way, scholars can identify patterns, emphases, and stylistic tendencies within texts.
Word frequency analysis can serve several purposes in literary research:
- It can reveal recurring themes or motifs by highlighting which words are most frequently used, offering insight into a text’s dominant concerns or rhetorical strategies.
- It can also be used to compare the linguistic style of different authors, genres, or historical periods, helping to map changes in diction, tone, or subject matter over time.
- In studies of individual works, frequency analysis can assist in tracking narrative focus or character development by examining how often certain names, places, or concepts appear across a text.
- Beyond individual texts, word frequency analysis can also support authorship attribution, genre classification, and the study of intertextuality.
We’ll explore which words were most frequently used in nine of Shakespeare’s plays and four of Marlowe’s, all included in our dataset. This analysis will help us gain insight into the themes and rhetoric of some of the most influential English plays written in 16th-century England.
Step 1: Loading the Dataset into the Script
Unlike the previous episode, where the dataset was stored in a single
.csv file, the dataset for this episode is stored in
thirteen separate .txt files. To store multiple texts in a
single Python variable, we can construct a Python
dictionary.
Python dictionaries are enclosed in curly brackets: { }. A Python dictionary is a built-in data structure used to store pairs of related information. One part of the pair is called the key, and the other part is the value. Each key is linked to a specific value, and you can use the key to quickly access the value associated with it. A Python dictionary is structured exactly like a linguistic dictionary: just as you look up a word in a linguistic dictionary to find its definition, you can store values under keys in a Python dictionary to be able to use the keys to retrieve the values later.
Here’s how you might define a Python dictionary:
PYTHON
my_vacation_plan= {
'budget': 100,
'destination': 'Johannesburg',
'accomodation': 'Sunset Hotel',
'activities': ['hiking', 'swimming', 'biking'],
'travel by plane': TRUE
}In a Python dictionary, both keys and values can be a variety of data types, but with some important rules:
Keys:
There are two main things to know about keys:
- They must be unique: You can’t have two identical keys in the same dictionary.
- They must be immutable: This means they have to be data types that cannot change.
Valid key types include:
- Strings (e.g., ‘budget’)
- Numbers (e.g., 1, 3.14)
- Tuples (e.g., (1, 2)), as long as the tuple itself doesn’t contain mutable objects
You cannot use lists, dictionaries, or other mutable types as keys.
We’re going to create two dictionaries: one for Marlowe’s plays, and
one for Shakespeare’s. The keys in each dictionary will be the names of
the .txt files — which correspond to the play titles — and
the values will be the full texts of the plays. First, let’s build a
list of keys for each dictionary:
PYTHON
import os
shakespeare_files = [f for f in os.listdir(shakespeare_path)]
marlowe_files = [f for f in os.listdir(marlowe_path)]
print("File names corresponding to Shakespeare:")
for file in shakespeare_files:
print ("*", file)
print()
print("File names corresponding to Marlowe:")
for file in marlowe_files:
print ("*", file)
Let’s analyze the code line by line
In the above code, we’re defining two lists:
shakespeare_files and marlowe_files.
A list in Python is a type of data structure used to store multiple items in a single variable. Lists can hold different types of data like numbers, strings, or even other lists. Items in a list are ordered, changeable (mutable), and allow duplicate values- meaning that the same value can appear multiple times in the list without any issue.
Python lists are enclosed in square brackets: [ ]. A Python list could look like this:
import osThis line imports Python’s built-in os module, which
provides functions for interacting with the operating system. This
includes functions to work with files and directories.
shakespeare_files = [f for f in os.listdir(shakespeare_path)]
marlowe_files = [f for f in os.listdir(marlowe_path)]This is a list comprehension, which is a short way to create a new
list using a for loop.
A for loop is used in Python to repeat an action for every item in a group (like a list). You can think of it as a way to go through a collection of things one by one and do something with each item. Here’s a basic idea:
for item in group:
do something with itemThe loop takes one item from the group, does something with it, then moves on to the next, until there are no more items left.
os.listdir(shakespeare_path)calls a function namedlistdir()from theosmodule. It takes the path to a directory (given inshakespeare_path) and returns a list of all the names of files and folders inside that directory.for f in os.listdir(shakespeare_path)is aforloop. It goes through each item in the list returned byos.listdir(shakespeare_path). For each item (each filename), it temporarily gives it the namef. So,fis a variable that holds each filename one by one.The list comprehension
[f for f in os.listdir(shakespeare_path)]basically says: “Take eachf(each filename) from the directory, and put it into a new list.” That new list is then assigned to the variableshakespeare_files.
marlowe_files is another list that is created through
the exact same process.
print("File names corresponding to Shakespeare:")
for file in shakespeare_files:
print ("*", file)
print()
print("File names corresponding to Marlowe:")
for file in marlowe_files:
print ("*", file)Having created these lists, we proceed to print their items one by
one, again using a for loop. Notice how the
for loop is being implemented here as compared to the list
comprehension above. Can you see the logic behind its syntax?
In order to use the file names as dictionary keys, we need to get rid
of their .txt extension. To do so, let’s write a function
that does exactly this for us. The function takes a list of file names,
removes their .txt extensions, and returns a list of file
names without extension:
PYTHON
def extention_remover (file_names):
filenames_without_extention = [file.removesuffix(".txt") for file in file_names]
return filenames_without_extentionNow let’s apply the function to shakespeare_files and
marlowe_files and store the results in two new lists,
shakespeare_works and marlowe_works. We’ll
print the resulting lists to make sure that the file extensions have
been successfully removed from them:
PYTHON
shakespeare_works= extention_remover(shakespeare_files)
marlowe_works= extention_remover(marlowe_files)
print (shakespeare_works)
print (marlowe_works)
So far, so good! Now we can create dictionaries containing all the
works by each author. To do this, we’ll define a function that handles
it for us. We’ll also incorporate the earlier steps - specifically,
reading file names from a directory and applying the
extension_remover function to strip their extensions. This
way, the new function can take the path to a folder containing our
literary works and return a dictionary where each file name (without the
extension) becomes a key, and the corresponding literary text becomes
the value:
PYTHON
def literary_work_loader (path):
def extention_remover (file_names):
filenames_without_extention = [file.removesuffix(".txt") for file in file_names]
return filenames_without_extention
file_names= [f for f in os.listdir(path)]
work_names= extention_remover (file_names)
full_text_dict= {}
for file, work in zip(file_names, work_names):
with open(f"{path}/{file}", "r", encoding="utf-8") as f:
full_text = f.read().replace("\n", "")
full_text_dict[work]= full_text
return full_text_dictLet’s analyze the code line by line
The first few lines of the above code are already familiar to you. So let’s only focus on the part where we are creating a dictionary:
full_text_dict= {}In this line, we are creating an empty dictionary and assigning it to
a variable named full_text_dict.
for file, work in zip(file_names, work_names):This line sets up a for loop. It lets us go through two
lists — file_names and work_names — at
the same time. The zip() function pairs up each
file name (with the .txt extension) and its matching
cleaned-up name (with no .txt extension). So for each step
in the loop:
-
filewill be the full file name (like “hamlet.txt”), and -
workwill be the name without the.txtpart (like “hamlet”).
with open(f"{path}/{file}", "r", encoding="utf-8") as f:This line opens a file so that we can read its contents.
-
f"{path}/{file}"is an f-string that builds the complete path to the file.
An f-string (short for formatted string) is a way to create strings that include variables inside them. It makes it easier to combine text and values without having to use complicated syntax. Here’s the basic idea:
name = "Bani"
greeting = f"Hello, {name}!"
print(greeting)Output: Hello, Bani!
The f before the opening quotation mark tells Python:
This is a formatted string. Inside the string, you can use curly braces
{ } to include variables (like name) or even expressions
(like 1 + 2).
If path equals “./data/shakespeare” and
file equals “hamlet.txt”, this becomes
“./data/shakespeare/hamlet.txt”.
-
"r"means we are opening the file in read mode (we are not changing it). -
encoding="utf-8"makes sure we can read special characters (like letters with accents). -
as fgives the file a nickname:f, so we can use it in the next line. - The
withkeyword automatically closes the file when we’re done reading it, which is a good habit.
full_text = f.read().replace("\n", "")-
f.read()reads the entire content of the file and stores it in a variable calledfull_text. -
.replace("\n", "")removes all the newline characters (\n) from the text by replacing them with a string with zero length, containing no characters (““). Normally, text files have line breaks. This line of code removes the line breaks and puts everything together in one big line of text.
full_text_dict[work] = full_textThis line adds a new entry to the full_text_dict
dictionary.
-
workis used as the key — that’s the cleaned-up name like “hamlet”. -
full_textis used as the value — that’s the complete content of the filehamlet.txt.
return full_text_dictThis line returns the dictionary we built. Whoever uses this function
will get back a dictionary with all the file names (without
.txt) as keys and their full texts as values.
Now that we have the function, we can use it to create two dictionaries containing the works of Shakespeare and Marlowe:
PYTHON
shakespeare_texts= literary_work_loader (shakespeare_path)
marlowe_texts= literary_work_loader (marlowe_path)Try printing the marlowe_texts dictionary, which is
shorter, to get an overview of its structure and content.
Step 2: Performing Word Frequency Analysis using spaCy
Performing word frequency analysis is faster and easier than you
think. This has become possible thanks to pretrained machine
learning models that the Python library spaCy
offers.
A pretrained machine learning model is a model that has already been trained on a large dataset by other developers. Instead of starting from scratch, you can use this model to perform tasks like image recognition, language processing, or object detection. It has already learned patterns and features from the data, so you don’t need to teach it everything again. This saves time, computing resources, and often improves accuracy, especially when you don’t have a lot of your own data to train a model from the beginning. You can also fine-tune it to work better on your specific task by giving it a smaller set of relevant data.
We are going to use spaCy’s en_core_web_md
model for this exercise. You can directly download the model from your
Jupyter Notebook by running the following code:
Once you have downloaded the en_core_web_md model, it remains on your computer, ensuring you don’t need to download it again the next time you run the following lines of code in Jupyter Notebook.
Now, we will write a function that takes the full text of each play, tokenizes it, and counts the number of times each word appears in that text.
Tokenizing a text means breaking a piece of text into smaller parts — usually words, subwords, or sentences — so that a computer can work with it more easily.
In natural language processing (NLP), tokenization is often the first step when preparing text for most analysis tasks like word frequency analysis, language modeling, translation, or sentiment analysis.
The following example demonstrates how a sentence can be tokenized:
text = "I love Python programming."
tokens = ['I', 'love', 'Python', 'programming']In this case, each word is a token. However, more advanced tokenizers (like those in NLTK, spaCy, or transformers) can handle punctuation, subwords, and special characters more intelligently.
Tokenization is important in NLP because computers don’t understand raw text.
PYTHON
import spacy
from collections import Counter
def token_count(text):
nlp = spacy.load("en_core_web_md")
doc = nlp(text)
words = [
token.lemma_.lower()
for token in doc
if token.is_alpha # Keep alphabetic tokens only
and not token.is_stop # Exclude stop words
and token.pos_ != "VERB" # Exclude verbs
]
return Counter(words)Challenge
Work with a partner and try to interpret the code above. Answer the following questions:
- What do the imported libraries do?
- What does the function do?
- Can you recognize the list comprehension in the function? How is is structured?
- What Python object does the function return? What shape could it possibly have?
Let’s analyze the code line by line and answer the above questions:
spacyis a library that helps Python understand and work with natural language or human language (text). It can tokenize text, recognize parts of speech (like nouns or verbs), and more.Counteris a class from thecollectionsmodule. It creates special dictionary-like objects that automatically count how often each item appears in an iterable, such as a list.The function
token_countprocesses a string of text and returns a count of specific words, excluding common words and verbs. Let’s break down what happens in the function step by step:
nlp = spacy.load("en_core_web_md")This line loads en_core_web_md, the pre-trained machine
learning model from spaCy that we have already downloaded,
and assigns it to the variable nlp. This model has been
trained on a large collection of English text and it can recognize
words, their part of speech (like nouns or verbs), their base forms
(lemmas), and more. We are assigning the loaded model
doc = nlp(text)Here, we use nlp to tokenize the text that is given to
the token_count function as an argument. The result is a
Doc object, stored in the variable doc. The
Doc object represents the entire text and contains a
sequence of Token objects. Each token is a word, punctuation mark, or
other meaningful unit that the model has identified.
From there, the function filters and counts certain words from
doc. We define which words these should be in the following
list comprehension.
words = [
token.lemma_.lower()
for token in doc
if token.is_alpha
and not token.is_stop
and token.pos_ != "VERB"
]This list comprehension has the following structure:
[token.lemma_.lower() for token in doc if ...]It means:
- Go through each word (
token) in the text (doc), - Convert it to its lemma (basic form, like “run” instead of “running”),
- Make it lowercase,
- But only include it if it’s a word (no punctuation), not a stop word, and not a verb.
Stop words are very common words in a language — like “the”, “and”, “is”, “in”, or “of”. These words are important for grammar, but they usually don’t carry much meaning on their own. In natural language processing, we often remove stop words because:
- They appear very frequently, so they dominate word counts.
- They don’t help us understand what the text is about.
- They’re similar across texts, so they’re not useful for comparing different documents.
We are also excluding verbs because, in performing this concrete word frequency analysis on the text of Marlowe and Shakespeare, we are more interested in nouns and adjectives, not in verbs.
The function returns a Counter object. This is like a
dictionary where:
- Each key is a word,
- Each value is the number of times that word appeared.
So the shape is something like:
{'word1': 3, 'word2': 1, 'word3': 2}We are now just one step away from obtaining the word frequencies in
the entire text collections by Marlowe and Shakespeare. While the
token_count function only counts words in a single text
file, we have dictionaries that contain multiple text files: four texts
by Marlowe and nine by Shakespeare.
Therefore, we need an additional function that takes a dictionary — not just a single text file — and counts the words in all the texts that exist as the values of keys in that dictionary. This approach allows us to count words not in a single text, but across a collection of texts written by a single author.
Writing this new function will be relatively easy, as we will
integrate the token_count function within it, which handles
most of the work for us.
PYTHON
def token_frequency_count (text_dict):
def token_count(text):
nlp = spacy.load("en_core_web_md")
doc = nlp(text)
words = [
token.lemma_.lower()
for token in doc
if token.is_alpha
and not token.is_stop
and token.pos_ != "VERB"
]
return Counter(words)
total_counts = Counter()
for key, value in text_dict.items():
total_counts += token_count (value)
return total_countsLet’s analyze the code’s last lines
The token_frequency_count function contains the
token_count function that we have written previously. After
defining the token_count function, we are creating
an empty Counter object (which has the structure of a
Python dictionary) and assigning it to the variable
total_counts.
Then, we are iterating through the keys and values of the input
dictionary, namely text_dict, using a for loop. The for
loop does the following:
- It treats each key-value pair as an
item. - It goes to the first item using its key, and reads the value of that key, which is the full text of a play.
- It uses the
token_countfunction to create aCounterobject containing all the desired words (tokens) from that text and adds thatCounterobject tototal_counts. - Then it goes to the next
item(key-value pair) intext_dictand performs the above operations again. It keeps counting words from every text intext_dictand adding them tototal_countsuntil it reaches the lastitemintext_dict.
Let’s apply the token_frequency_count function to the
dictionaries we have created from the Marlowe and Shakespeare texts and
take a look at the frequency of words used in the texts written by
Marlowe as an example:
PYTHON
shakespeare_frequency = token_frequency_count (shakespeare_texts)
marlowe_frequency = token_frequency_count (marlowe_texts)
marlowe_frequency
The output above displays some of the most frequent words used by Christopher Marlowe in the four plays we are analyzing.
In your Jupyter Notebook, also display the frequency of words used by Shakespeare and compare both results.
As you can see, comparing the two results can be time-consuming and unintuitive, as they are not displayed next to each other in Jupyter Notebook.
Therefore, in the next step, we will visualize these word frequencies to gain a better overview of the contents of the texts written by each playwright. This will also allow us to compare their linguistic styles and literary themes.
Step 3: Visualizing Word Frequencies
We have already worked with the plotly.express module in
the previous episode, where we visualized dataframes. We will implement
the same module in this episode as well.
Let’s write a function that takes a Counter object
containing a dictionary of word frequencies (freq_dict),
the number of the most frequent words to display in the graph
(top_n), and the title of the graph (title) as
parameters. This function will create a bar chart of the frequency of
the selected words within the Counter object:
PYTHON
import plotly.express as px
import pandas as pd
def plot_frequencies (freq_dict, top_n, title):
most_common = freq_dict.most_common(top_n)
df = pd.DataFrame(most_common, columns=['word', 'frequency'])
fig = px.bar(df, x='word', y='frequency', title=title, text='frequency')
fig.show()Let’s analyze the code’s last lines
most_common = freq_dict.most_common(top_n)This line gets the top n most frequent words from
freq_dict and stores them in a list we have called
most_common. This list contains tuples that look
like this: (word, frequency). So, for example, the
value stored in most_common for the top three words that
appear in Shakespeare plays would be:
[('thou', 1136), ('shall', 759), ('thy', 725)]
A tuple in Python is a collection data type used to store multiple
items in a single variable, characterized by its immutability, meaning
that once created, its contents cannot be changed; it maintains the
order of elements, ensuring they appear in the same sequence as defined;
and it can contain heterogeneous data types, allowing for integers,
strings, and even other tuples within a single tuple. Tuples are defined
using parentheses and commas, such as in the example:
(1, "apple", 3.14, True).
df = pd.DataFrame(most_common, columns=['word', 'frequency'])This turns the most_common list into a dataframe using
pandas and stores the dataframe in a variable named
df. It gives the columns the names ‘word’ and ‘frequency’.
The dataframe format is what plotly expects when making a
chart.
fig = px.bar(df, x='word', y='frequency', title=title, text='frequency')
fig.show()The first line creates a bar chart using the express
module from the plotly library. It takes the following
arguments:
-
df: the dataframe created in the previous line -
x='word': words go on the x-axis -
y='frequency': their counts go on the y-axis -
title=title: the chart gets the title that is passed to the function. -
text='frequency': shows word frequencies above the bars for clarity
Finally, fig.show() displays the chart in Jupyter
Notebook.
Now that we have the function, let’s pass the necessary arguments to it and visualize two bar charts displaying the 20 most frequent words that appear in the Marlowe and Shakespeare plays:
PYTHON
plot_frequencies(shakespeare_frequency, 20, "Top 20 Words in Shakespeare's Works")
plot_frequencies(marlowe_frequency, 20, "Top 20 Words in Marlowe's Works")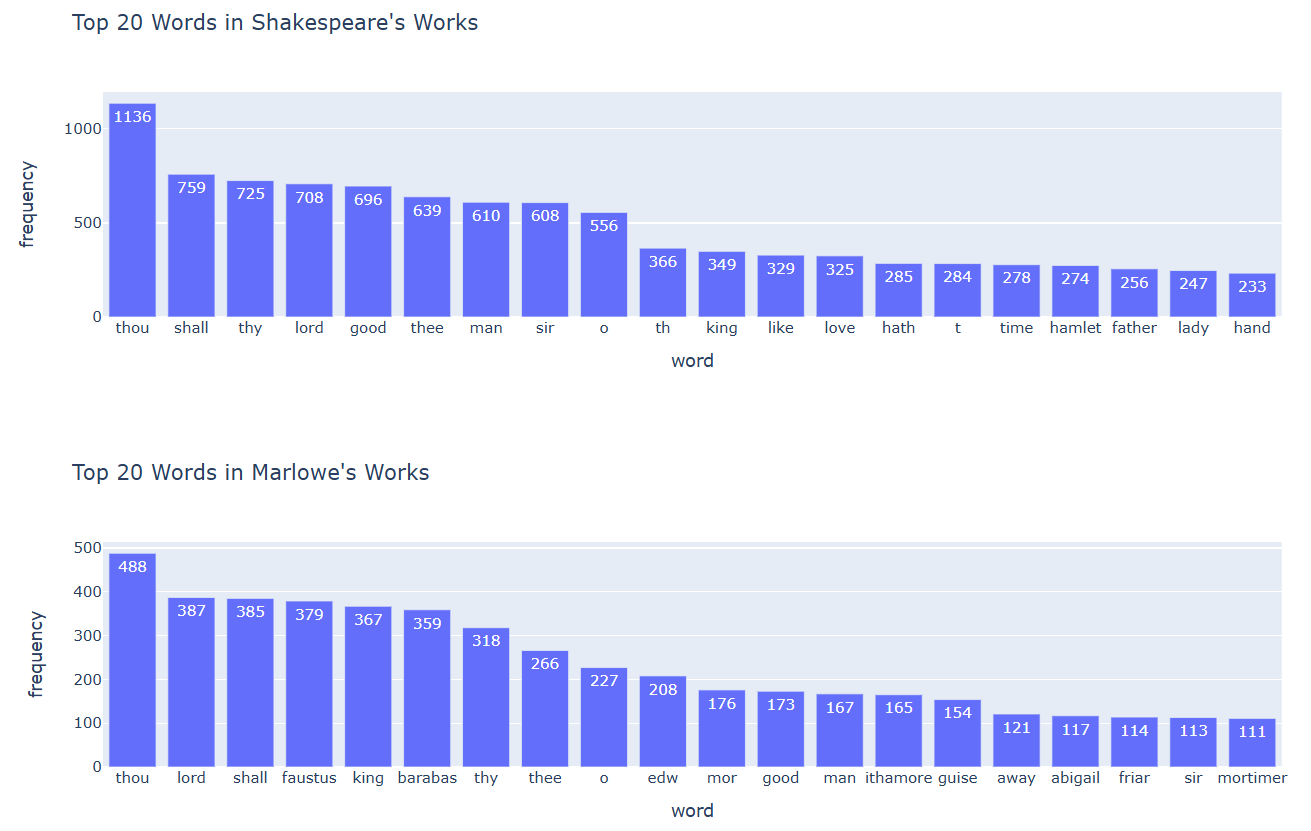
In a group, interpret the bar charts you have just visualized:
What information do these word frequencies reveal about the content and style of the plays written by the two selected playwrights?
Are there any common words among the 20 most frequent words from the works of each playwright? What do these commonalities indicate about the style of English playwrights from the 16th century?
Do you think this observation can be generalized to all 16th-century authors from England? Why or why not?
2. Creating a Word Cloud
Another way to visualize the most frequent words in a text is by creating a word cloud. Word clouds are visual representations of text data where the size of each word indicates its frequency.
There is a specific Python library named WordCloud that
does exactly this for you. To visualize a word cloud, we will use single
texts rather than the entire text collection by each author. Let’s write
code that visualizes a word cloud for Shakespeare’s early play, “Comedy
of Errors”:
PYTHON
import matplotlib.pyplot as plt
from wordcloud import WordCloud
text = shakespeare_texts['comedy_of_errors']
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text)
plt.figure(figsize=(10, 5))
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis('off')
plt.show()
Let’s analyze the code line by line
In this analysis, only lines of code are included that may be new to you.
from wordcloud import WordCloudHere, we are importing the WordCloud class from the
wordcloud library. This library is specifically designed to
create word clouds.
wordcloud = WordCloud(width=800, height=400, background_color='white').generate(text)In this line, we create an instance of the WordCloud
class with specific parameters:
-
width=800: Sets the width of the word cloud image to 800 pixels. -
height=400: Sets the height of the word cloud image to 400 pixels. -
background_color='white': Sets the background color of the word cloud to white.
The .generate(text) method takes the text
variable (which contains the Shakespeare play) and generates the word
cloud based on the frequency of words in that text. The result is stored
in the variable wordcloud.
plt.figure(figsize=(10, 5))This line creates a new figure for plotting with a specified size.
The figsize parameter sets the dimensions of the figure to
10 inches wide and 5 inches tall.
plt.imshow(wordcloud, interpolation='bilinear')Here, we use the imshow function to display the
generated word cloud image. The interpolation='bilinear'
argument is used to improve the appearance of the image by smoothing it,
which can make it look better when resized.
plt.axis('off')This line turns off the axes of the plot. By default, plots have axes that show the scale, but for a word cloud, we typically want to hide these axes to focus on the visual representation of the words.
Reflect
Look again at the word cloud we have created. Can you identify the names of the play’s main characters?
3. Keyword-in-Context (KWIC) Analysis
In the previous section on word frequency analysis, we saw that counting the frequency of words in a body of work can provide some information on the style and themes of literary works written by certain authors or in a certain epoch.
These words and their contribution to style and meaning can be analyzed even more effectively if you look at the context they appear in. Keyword-in-context (kwic) analysis allows you to automate the search for the context in which each word appears.
In this section, I’m going to present you with a simple code that does exactly this for you:
PYTHON
import nltk
from nltk.text import Text
from nltk.tokenize import word_tokenize
nltk.download('punkt') #run this line only once and then comment it out.
def kwic_analyze (text, keyword, width=140, lines=20):
tokens = word_tokenize(text)
nltk_text = Text(tokens)
nltk_text.concordance(keyword, width=width, lines=lines)
kwic_analyze (marlowe_texts['jew_of_malta'], "lord", width=120, lines= 20)
Can you tell how the above code works?
If you have studied this Python lesson from the very beginning and mastered the concepts and methods from Episode 1 up to this point, you should be able to understand what the above code does.
Experiment with the arguments you are passing to the
kwic_analyze function and observe the output. What does
each argument do within the function?
import nltkThis imports the Natural Language Toolkit (NLTK)
library. NLTK is a popular Python library for processing
and analyzing natural language (text).
from nltk.text import TextThis imports the Text class from the
nltk.text module. The Text class provides
useful tools for analyzing text, including functions like
concordance() for keyword-in-context (KWIC) analysis.
from nltk.tokenize import word_tokenizeThis imports the word_tokenize function from
NLTK. It tokenizes a string of text by breaking it into
individual words and punctuation marks.
nltk.download('punkt')This downloads the punkt tokenizer model, which
word_tokenize depends on to split text into words. Once you
have downloaded this model, you can comment out this line of code
because you don’t need it any more.
def kwic_analyze (text, keyword, width=140, lines=20):This defines a function named kwic_analyze that takes
four parameters:
-
text: the full text you want to search -
keyword: the word you want to find in context -
width: how many characters of context to show around the keyword (default is 140) -
lines: how many keyword matches to display (default is 20)
tokens = word_tokenize(text)This breaks the input text into a list of tokens, using the
word_tokenize function.
nltk_text = Text(tokens)This creates an nltk.Text object from the list of
tokens. This object lets you use text analysis methods, such as
concordance().
nltk_text.concordance(keyword, width=width, lines=lines)This searches the text for the given keyword and displays each occurrence in context.
-
widthcontrols how much surrounding text is shown. -
lineslimits how many matches to show.
Challenge
Can you write a function that takes the dictionary containing all
works by an author — instead of taking only one text — as well as the
keyword, width of the context, and number of lines, and returns that
keyword in the context of each one of the texts within the dictionary?
You can integrate the kwic_analyze function from above into
the function that you are writing.
PYTHON
import nltk
from nltk.text import Text
from nltk.tokenize import word_tokenize
def kwic_analyze_all(texts_dict, keyword, width=140, lines=20):
def kwic_analyze(text, keyword, width=width, lines=lines):
tokens = word_tokenize(text)
nltk_text = Text(tokens)
nltk_text.concordance(keyword, width=width, lines=lines)
for title, text in texts_dict.items():
print(f"\nContext for '{keyword}' in '{title}':")
print()
kwic_analyze(text, keyword, width, lines)Reflect
Examine other plays by both authors and display the keyword “lord” in its context within these texts. Does the word, in each context, refer to “God,” or is it used to address a person of higher social rank?
Is there a relationship between these use cases and the genre and topic of the plays?
KWIC analysis allows you to see the context in which each keyword appears. It is helpful when you want to quickly examine the texts you are analyzing and the context of individual keywords without performing a close reading of the text.
If these contexts seem relevant to you as a researcher, you can consider reading the entire text to gain an even better understanding of the contexts of the keywords on which your research is focused.
- Formulate appropriate quantitative research questions when working with data composed of literary texts.
- Learn about lists, for loops, f-strings, and tuples in Python.
- Get to know and use the Python libraries spaCy, wordcloud, and NLTK.
- Perform word frequency analysis using spaCy.
- Generate word clouds using worldcloud.
- Perform keywprd-in-context analysis using NLTK.